[210209] java StringTokenizer
java.util.StringTokenizer
public class StringTokenizer
extends Object
implements Enumeration<Object>
public StringTokenizer(@NotNull String str,
String delim,
boolean returnDelims)
- str : 토큰으로 분리할 문자열
- delim : 구분자. 값을 주지 않을 경우 공백으로 설정된다.
- returnDelims : 구분자를 반환하지 하지 않을지를 결정한다.
- false일 경우 (default) : 구분자 기준으로 토큰이 분리된다. 토큰은 구분자가 아닌 문자이다.
- true일 경우 : 구분자를 포함해서 토큰이 분리된다. 토큰은 구분자이거나, 다른 문자이다.
stringTokenizer 클래스는 문자열을 토큰으로 분리해준다. 그리고 내부에 토큰화된 string의 위치를 저장한다. iterator와 유사하게 hasMofeTokens(), nextToken() 메소드를 사용해서 남은 토큰이 있는지 확인하고 다음 위치에 있는 토큰을 불러올 수 있다.
현재는 래거시 클래스로 분류되며, 이보다는 split() 메소드 사용을 권장한다고 한다. 하지만 속도가 빨라서 백준 등의 알고리즘 문제 풀이에는 아직까지도 사용되고 있는 것 같다.
Example
1. 주어진 문자열을 구분자로 분류하는 예제
StringTokenizer st = new StringTokenizer("apple grape strawberry orange");
while(st.hasMoreTokens()){
System.out.println(st.nextToken());
}hasMoreTokens() 메소드를 사용해서 StringTokenizer 객체에 남아있는 토큰이 있는지 확인하고, 있다면 nextToken() 메소드를 사용해서 다음 토큰을 불러온 뒤 출력한다.
- 실행 결과
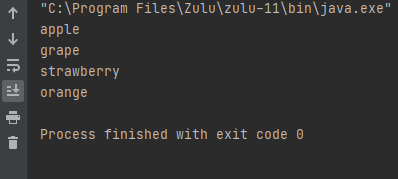
기본적으로 공백을 기준으로 토큰을 분리하는 걸 알 수 있다.
2. 구분자를 줬을 경우
StringTokenizer st = new StringTokenizer("apple grape strawberry orange","a");
while(st.hasMoreTokens()){
System.out.println(st.nextToken());
}문자 "a"를 구분자로 넘겨주었다.
- 실행 결과

"a" 문자의 등장점을 기준으로 토큰을 분리한 것을 확인할 수 있다.
3. returnDelims 값을 true로 했을 경우
StringTokenizer st = new StringTokenizer("apple grape strawberry orange"," ", true);
System.out.println("returnDelims : true");
while(st.hasMoreTokens()){
System.out.println(st.nextToken());
}
StringTokenizer st2 = new StringTokenizer("apple grape strawberry orange"," ", false);
System.out.println("returnDelims : false");
while(st2.hasMoreTokens()){
System.out.println(st2.nextToken());
}StringTokenizer는 재사용이 불가능하기 때문에, 두 개의 StringTokenizer 객체를 생성해서 예제를 만들었다.
- 실행 결과

returnDelims의 값이 true일 때는 구분자도 토큰에 포함하며, false일 때는 구분자를 토큰에 포함하지 않는 것을 확인할 수 있다.
4. countTokens()
StringTokenizer st = new StringTokenizer("apple grape strawberry orange"," ", true);
System.out.println("returnDelims : true");
while(st.hasMoreTokens()){
System.out.println("numOfToken : " + st.countTokens());
System.out.println(st.nextToken());
}StringTokenizer 객체에 남아있는 토큰의 수를 return한다.
- 실행 결과

StringTokenizer vs Scanner vs split
StringTokenizer : 래거시 클래스로 호환성을 위해 남아있으며 이보다는 split의 사용을 권장한다. split 보다 속도가 빠르다.
Scanner : 외부 문자열을 분리하는 데 효율적이다.
split : String 클래스에서 쉽게 가져다 쓸 수 있고, 토큰으로 문자열을 분리한 결과를 배열의 형태로 저장할 수 있다. 정규식을 사용하기 때문에 유연한 문자열 분리가 가능하다. 그러나, 정규식 패턴을 컴파일해야 하기 때문에 StringTokenizer에 비해서 속도가 느리다.
- reference
docs.oracle.com/javase/8/docs/api/java/util/StringTokenizer.html
stackoverflow.com/questions/691184/scanner-vs-stringtokenizer-vs-string-split